
Прогнозирование временных рядов
- Алгоритмы
Привет.
Я хочу рассказать об одной задаче, которая очень заинтересовала меня в свое время, а именно, о задаче прогнозирования временных рядов и решении этой задачи методом муравьиного алгоритма.
Для начала вкратце о задаче и о самом алгоритме:
Прогнозирование временных рядов подразумевает, что известно значение некой функции в первых n точках временного ряда. Используя эту информацию необходимо спрогнозировать значение в n+1 точке временного ряда. Существует множество различных методов прогнозирования, но на сегодняшний день одними из самых распространенных являются метод Винтерса и ARIMA модель. Подробнее о них можно почитать .
О том что такое муравьиный алгоритм говорилось уже довольно много. Для тех кому лень лезть, например, сюда , перескажу. Вкратце, муравьиный алгоритм это моделирование поведения муравьиной колонии в их стремлении найти кратчайший путь к источнику еды. Муравьи, при движении оставляют за собой след феромона, который влияет на вероятность выбора муравьем данного пути. Учитывая то, что муравьи будут за один и тот же промежуток времени пройти короткий путь бОльшее количество раз, на нем будет оставаться больше феромона. Таким образом, с течением времени, все больше муравьев будут выбирать кратчайший путь к источнику пищи.
Для наглядности, вставлю картинку:
Теперь, перейдем непосредственно к решению задачи прогнозирования методом муравьиных колоний.
Первая проблема с которой мы сталкиваемся - необходимо представить временной ряд в виде графа, на котором будем запускать муравьиный алгоритм.
Было найдено два возможных решения:
1. Представить временной ряд в виде мультиграфа где из каждой точки временного ряда можно перейти в каждую набором определенных приростов. (Для облегчения задачи будем брать нормализованные значения на промежутке от -1 до 1). Это был первый подход, который мы попробовали. Он показал неплохой результат на временных рядах малой размерности, но с увеличением размерности стала резко падать как точность прогноза, так и производительность, поэтому от этого варианта отказались.
2. Представить временной ряд в виде набора сцепленых графов, где каждый граф отвечает за свою величину прироста значения временного ряда. иначе говоря, имеем граф который отвечает за прирост -1, -0,9… и так до 1. Шаг, естественно, можно уменьшить, или увеличить, что скажется на точности прогноза и ресурсоемкости задачи.(в конечном итоге этот вариант оказался наиболее удачным.)
На этом наборе сцепленных графов, запускался муравьиный алгоритм(на каждом графе свой), который откладывал феромон на ребрах, соответствующих известным значениям временного ряда. Причем, при откладывании феромона на графе i, феромон также откладывался на графах i-1и i+1, но в гораздо меньшем количестве(в нашем случае 1/10 от базового количества феромона) таким образом, муравьи выделяли наиболее часто встречающиеся последовательности прироста значения временного ряда, а за счет откладывания феромона на смежные графы, нивелировалась возможная погрешность и изначальная зашумленность временного ряда.
Данный алгоритм мы тестировали на искусственно подготовленных временных рядах с разным уровнем периодичности и шума. Результат получился двояким. С одной стороны, при уровнях шума до 0,3 алгоритм показывает высокие результаты прогноза, сравнимые с результатами ARIMA модели. На более высоких уровнях шума возникает большой разброс результатов: прогноз то очень точный, то совершенно неправильный.
В настоящий момент мы работаем над подбором оптимального значения параметров алгоритма и некоторыми методами его улучшения, о которых я напишу как только они будут в достаточной степени проверены.
Спасибо всем за внимание.
Upd:
Постараюсь ответить на возникшие вопросы.
Мультиграф - это граф, каждая вершина которого соединена с каждой.
Хаотические ряды, как уже писали ниже, не случайны. Вы можете посмотреть на изображения ряда Лоренца в 3-х мерном пространстве и увидите цикличность движения. Просто определить эту цикличность сложно, и на первый взгляд ряд выглядит случайным.
Значения временного ряда нормализуются на промежутке -1...1 и записываются в граф. Граф - в данном случае таблица переходов из вершины в вершину. Феромон откладывается на ребра(в ячейки таблицы).
В случае со сцепленными графами используется несколько таблиц, каждая из которых отвечает только за свою величину перехода.
В зависимости от количества феромона в той, или иной ячейке, выбирается то, или иное значение временного ряда, как результат прогноза.
Алгоритм тестировали, преимущественно, на ряде Лоренца.
На данный момент рано говорить о том насколько он лучше или хуже. Похоже, что алгоритм подвержен нахождению псевдопериодов и с ростом уровня шума количество ложных периодов возрастает.
С другой стороны, при удачно подборе параметров точность прогноза достаточно высокая(отклонение до 7-10 процентов, что для хаотического ряда неплохо.)
К тестированию на реальных данным перейдем позже. Картинки постараюсь подготовить и добавить в ближайшее время.
Спасибо за внимание.
Скачать полный текст диссертации в формате PDF (2.9 Мб).
Глава 1. Постановка задачи и обзор моделей прогнозирования временных рядов
В текст диссертации включены вставки со ссылками на полезные записи блога, в которых я простым языком рассказываю о моделях прогнозирования и привожу примеры реализации.Нейронные сети рассмотрены в наборе записей по тэгу .
- Модель ARIMAX подробно описана в четырех записях по тэгу .
- Описание и примеры реализации экспоненциального сглаживания приведены по тэгу .
- Опубликованы записи по вопросам .
- Полный перечень материалов о моделях прогнозирования смотри по тэгу .
Слово прогноз возникло от греческого , что означает предвидение, предсказание. Под прогнозированием понимают предсказание будущего с помощью научных методов . Процессом прогнозирования называется специальное научное исследование конкретных перспектив развития какого-либо процесса. Согласно работе процессы, перспективы которых необходимо предсказывать, чаще всего описываются временными рядами , то есть последовательностью значений некоторых величин, полученных в определенные моменты времени. Временной ряд включает в себя два обязательных элемента - отметку времени и значение показателя ряда, полученное тем или иным способом и соответствующее указанной отметке времени. Каждый временной ряд рассматривается как выборочная реализация из бесконечной популяции, генерируемой стохастическим процессом, на который оказывают влияние множество факторов . На представлен пример временного ряда цен на электроэнергию европейской территории РФ.

Рис. 1.1 Временной ряд цен на электроэнергию
Простым языком о видах временных рядов смотри запись блога Характеристики прогнозируемых временных рядов
Одна из классификаций временных рядов приведена в работе . Согласно этой работе, временные ряды различаются способом определения значения, временным шагом, памятью и стационарностью.
- интервальные временные ряды ,
- моментные временные ряды .
Интервальный временной ряд представляет собой последовательность, в которой уровень явления (значение временного ряда) относят к результату, накопленному или вновь произведенному за определенный интервал времени. Интервальным, например, является временной ряд показателя выпуска продукции предприятием за неделю, месяц или год; объем воды, сброшенной гидроэлектростанцией за час, день, месяц; объем электроэнергии, произведенной за час, день, месяц и другие.
Если же значение временного ряда характеризует изучаемое явление в конкретный момент времени, то совокупность таких значений образует моментный временной ряд . Примерами моментных рядов являются последовательности финансовых индексов, рыночных цен; физические показатели, такие как температура окружающего воздуха, влажность, давление, измеренные в конкретные моменты времени, и другие.
В зависимости от частоты определения значений временного ряда, они делятся на
- равноотстоящие временные ряды ,
- неравноотстоящие временные ряды .
Равноотстоящие временные ряды формируются при исследовании и фиксации значений процесса в следующие друг за другом равные интервалы времени. Большинство физических процессов описываются при помощи равноотстоящих временных рядов. Неравноотстоящими временными рядами называются те ряды, для которых принцип равенства интервалов фиксации значений не выполняется. К таким рядам относятся, например, все биржевые индексы в связи с тем, что их значения определяются лишь в рабочие дни недели.
В зависимости от характера описываемого процесса временные ряды разделяются на
- временные ряды длинной памяти ,
- временные ряды короткой памяти .
Задача отнесения временного ряда к рядам с короткой или длинной памятью описана в статье . В целом, говоря о временных рядах с длинной памятью , подразумеваются временные ряды, для которых автокорреляционная функция, введенная в книге , убывает медленно. К временным рядам с короткой памятью относят временные ряды, автокорреляционная функция которых убывает быстро. Скорость потока транспорта по дорогам, а также многие физические процессы, такие как потребление электроэнергии, температура воздуха, относятся к временным рядам с длинной памятью . К временным рядам с короткой памятью относятся, например, временные ряды биржевых индексов.
Дополнительно временные ряды принято разделять на
- стационарные временные ряды ,
- нестационарные временные ряды .
Стационарным временным рядом называется такой ряд, который остается в равновесии относительно постоянного среднего уровня. Остальные временные ряды являются нестационарными . В книге указано, что и в промышленности, и в торговле, и в экономике, где прогнозирование имеет важное значение, многие временные ряды являются нестационарными, то есть не имеющими естественного среднего значения. Нестационарные временные ряды для решения задачи прогнозирования часто приводятся к стационарным при помощи разностного оператора .
Горизонты прогнозирования рассмотрены также в записи блога Горизонты прогнозирования временных рядов
- ультра: до 3 – 4 часа;
- краткосрочное прогнозирование : до 5 – 8 часов;
- : до 16 – 24 часов.
Для задачи прогнозирования энергопотребления классификация задач предложена в работе :
- : до одного дня;
- краткосрочное прогнозирование : от одного дня до недели;
- среднесрочное прогнозирование : от одной недели до года;
- долгосрочное прогнозирование : более чем на год вперед.
То есть для различных временных рядов , с различным временным разрешением классификация срочности задач прогнозирования индивидуальна .
Говоря о прогнозировании временных рядов, необходимо различить два взаимосвязанных понятия - метод прогнозирования и .
Метод прогнозирования представляет собой последовательность действий , которые нужно совершить для получения модели прогнозирования временного ряда.
Метод прогнозирования содержит последовательность действий, в результате выполнения которой определяется конкретного временного ряда. Кроме того, метод прогнозирования содержит действия по оценке качества прогнозных значений. Общий итеративный подход к построению модели прогнозирования состоит из следующий шагов .
Шаг 1. На первом шаге на основании предыдущего собственного или стороннего опыта выбирается общий класс моделей для прогнозирования временного ряда на заданный горизонт.
Шаг 2. Определенный общий класс моделей обширен. Для непосредственной подгонки к исходному временному ряду, развиваются грубые методы идентификации подклассов моделей. Такие методы идентификации используют качественные оценки временного ряда.
Шаг 3. После определения подкласса модели, необходимо оценить ее параметры , если модель содержит параметры, или структуру, если модель относится к категории структурных моделей (). На данном этапе обычно используется итеративные способы, когда производится оценка участка (или всего) временного ряда при различных значениях изменяемых величин. Как правило, данный шаг является наиболее трудоемким в связи с тем, что часто в расчет принимаются все доступные исторические значения временного ряда.
Шаг 4. Далее производится диагностическая проверка полученной модели прогнозирования . Чаще всего выбирается участок или несколько участков временного ряда, достаточных по длине для проверочного прогнозирования и последующей оценки точности прогноза. Выбранные для диагностики модели прогнозирования участки временного ряда называются контрольными участками (периодами).
Шаг 5. В случае если точность диагностического прогнозирования оказалась приемлемой для задач, в которых используются прогнозные значения, то модель готова к использованию . В случае если точность прогнозирования оказалось недостаточной для последующего использования прогнозных значений, то возможно итеративное повторение всех описанных выше шагов, начиная с первого.
Моделью прогнозирования временного ряда является функциональное представление, адекватно описывающее временной ряд.
При прогнозировании временных рядов возможны два варианта постановки задачи . В первом варианте для получения будущих значений исследуемого временного ряда используются доступные значения только этого ряда . Во втором варианте для получения прогнозных значений возможно использование не только фактических значений искомого ряда, но и значений набора внешних факторов, представленных в виде временных рядов . В общем случае временные ряды внешних факторов могут иметь разрешение по времени отличное от разрешения искомого временного ряда. Например, в работе подробно обсуждаются внешние факторы, оказывающие влияние на временной ряд энергопотребления. К таким внешним факторам относят температуру окружающей среды, влажность воздуха, а также сезонность, т. е. час суток, день недели, месяц года. В общем случае внешние факторы могут быть дискретными , т. е. представленными временными рядами, например, температура воздуха; или категориальными , т. е. состоящими из подмножеств, например, в зависимости от веса тела человека можно отнести к трем категориям: «легкий», «средний», «тяжелый». Лишь некоторые модели прогнозирования позволяют учитывать категориальные внешние факторы, большинство моделей позволяют учитывать только дискретных ().
При прогнозировании временного ряда , адекватно описывающую временной ряд, которая называется моделью прогнозирования . Цель создания модели прогнозирования состоит в получении такой модели, для которой среднее абсолютное отклонение истинного значения от прогнозируемого стремится к минимальному для заданного горизонта, который называется временем упреждения. После того, как модель прогнозирования временного ряда определена, требуется вычислить будущие значения временного ряда, а также их доверительный интервал.
1.2. Формальная постановка задачи
Прогнозирование без учета внешних факторов . Пусть значения временного ряда доступны в дискретные моменты времени t = 1,2,...,T . Обозначим временной ряд Z(t) = Z(1), Z(2),...,Z(T) . В момент времени T необходимо определить значения процесса Z(t) в моменты времени T+1,...,T+P . Момент времени T называется моментом прогноза, а величина P - временем упреждения .
1) Для вычисления значений временного ряда в будущие моменты времени требуется определить функциональную зависимость , отражающую связь между прошлыми и будущими значениями этого ряда

Рис. 1.2. Иллюстрация задачи прогнозирования временного ряда без учета внешних факторов
Прогнозирование с учетом внешних факторов . Пусть значения исходного временного ряда Z(t) доступны в дискретные моменты времени t = 1,2,...,T . Предполагается, что на значения Z(t) оказывает влияние набор внешних факторов. Пусть первый внешний фактор X 1 (t 1) доступен в дискретные моменты времени t 1 = 1,2,...,T 1 , второй внешний фактор X 2 (t 2) доступен в моменты времени t 2 = 1,2,...,T 2 и т.д.
В случае, если дискретность исходного временного ряда и внешних факторов, а также значения T,T 1 ,...,T S различны, то временные ряды внешних факторов X 1 (t 1) ,...,X S (t S) необходимо привести к единой шкале времени t .
В момент прогноза T необходимо определить будущие значения исходного процесса Z(t) в моменты времени T+1,...,T+P , учитывая влияние внешних факторов X 1 (t) ,...,X S (t) . При этом считаем, что значения внешних факторов в моменты времени X 1 (T+1) ,...,X 1 (T+P) ,...,X S (T+1) ,...,X S (T+P) являются доступными.
1) Для вычисления будущих значений процесса Z(t) в указанные моменты времени требуется определить функциональную зависимость , отражающую связь между прошлыми значениями Z(t) и будущими, а также принимающую во внимание влияние внешних факторов X 1 (t) ,...,X S (t) на исходный временной ряд
2) Кроме получения будущих значений требуется определить доверительный интервал возможных отклонений этих значений.
Задача прогнозирования временного ряда с учетом одного внешнего фактора представлена на

Рис. 1.3. Иллюстрация задачи прогнозирования временного ряда с учетом внешнего фактора
1.3. Обзор моделей прогнозирования
Перед тем как перейти к обзору моделей, необходимо отметить, что названия моделей и соответствующих методов как правило совпадают . Например, работы , , , посвящены одной из самых распространенных моделей прогнозирования авторегрессия проинтегрированного скользящего среднего с учетом внешнего фактора (auto regression moving average external, ). Эту модель и соответствующий ей метод обычно называют . В настоящее время принято использовать английские аббревиатуры названий как моделей, так и методов.
Набор понятных для чтения материалов по вопросу классификации моделей и методов прогнозирования временных рядов можно найти по тегу .
Линейная регрессионная модель . Самым простым вариантом регрессионной модели является линейная регрессия. В основу модели положено предположение, что существует дискретный внешний фактор X(t) , оказывающий влияние на исследуемый процесс Z(t) , при этом связь между процессом и внешним фактором линейна. Модель прогнозирования на основании линейной регрессии описывается уравнением
где α 0 и α 1 - коэффициенты регрессии; ε t - ошибка модели. Для получения прогнозных значений Z(t) в момент времени t необходимо иметь значение X(t) в тот же момент времени t , что редко выполнимо на практике.
Множественная регрессионная модель . На практике на процесс Z(t) оказывают влияние целый ряд дискретных внешних факторов X 1 (t) ,…,X S (t) . Тогда модель прогнозирования имеет вид
Недостатком данной модели является то, что для вычисления будущего значения процесса Z(t) необходимо знать будущие значения всех факторов X 1 (t) ,…,X S (t) , что почти невыполнимо на практике.
В основу нелинейной регрессионной модели положено предположение о том, что существует известная функция, описывающая зависимость между исходным процессом Z(t) и внешним фактором X(t)
В рамках построения модели прогнозирования необходимо определить параметры функции A . Например, можно предположить, что
Для построения модели достаточно определить параметры ![]() . Однако на практике редко встречаются процессы, для которых вид функциональной зависимости между процессом Z(t)
и внешним фактором X(t)
заранее известен. В связи с этим нелинейные регрессионные модели применяются редко
.
. Однако на практике редко встречаются процессы, для которых вид функциональной зависимости между процессом Z(t)
и внешним фактором X(t)
заранее известен. В связи с этим нелинейные регрессионные модели применяются редко
.
Модель группового учета аргументов (МГУА) была разработана Ивахтенко А.Г. . Модель имеет вид
 (1.9)
(1.9)
Другой тип модели имеет большое значение в описании временных рядов и часто используется совместно с авторегрессией называется моделью скользящего среднего порядка q и описывается уравнением
Авторегрессионнная модель с распределенным лагом (autoregressive distributed lag models, ARDLM) недостаточно подробно описана в литературе. Основное внимание данной модели уделяется в книгах по эконометрике .
Часто при моделировании процессов на изучаемую переменную влияют не только текущие значения процесса, но и его лаги, то есть значения временного ряда, предшествующие изучаемому моменту времени. Модель авторегрессии распределенного лага описывается уравнением
Здесь φ 0 ,..., φ p - коэффициенты, l - величина лага. Модель () называется ARDLM(p,l) и чаще всего применяется для моделирования экономических процессов .
1.3.3. Модели экспоненциального сглаживания
Примеры реализации экспоненциального сглаживания можно найти по тэгу .
Модели экспоненциального сглаживания разработаны в середине XX века и до сегодняшнего дня являются широко распространенными в силу их простоты и наглядности.
Модель экспоненциального сглаживания (exponential smoothing, ES) применяется для моделирования финансовых и экономических процессов . В основу экспоненциального сглаживания заложена идея постоянного пересмотра прогнозных значений по мере поступления фактических. Модель ES присваивает экспоненциально убывающие веса наблюдениям по мере их старения. Таким образом, последние доступные наблюдения имеют большее влияние на прогнозное значение, чем старшие наблюдения.
Функция модели ES имеет вид
где α - коэффициент сглаживания, 0 < α < 1 ; начальные условия определяются как S(1) = Z(0) . В данной модели каждое последующее сглаженное значение S(t) является взвешенным средним между предыдущим значением временного ряда Z(t) и предыдущего сглаженного значения S(t-1) .
Модель Хольта или двойное экспоненциальное сглаживание применяется для моделирования процессов, имеющих тренд . В этом случае в модели необходимо рассматривать две составляющие: уровень и тренд . Уровень и тренд сглаживаются отдельно
 (1.17)
(1.17)
Здесь α - коэффициент сглаживания уровня, как и в модели (1.16), γ - коэффициент сглаживания тренда.
Модель Хольта-Винтерса или тройное экспоненциальное сглаживание применяется для процессов, которые имеют тренд и сезонную составляющую
Здесь R(t) - сглаженный уровень без учета сезонной составляющей
G(t) - сглаженный тренд
а S(t) - сезонная составляющая
Величина L определяется длиной сезона исследуемого процесса. Модели экспоненциального сглаживания наиболее популярны для долгосрочного прогнозирования .
1.3.4. Нейросетевые модели
Набор читабельных материалов с примерами реализации нейронных сетей можно найти по тэгу
В настоящее время самой популярной среди структурных моделей является модель на основе искусственных нейронных сетей (artificial neural network, ANN) . Нейронные сети состоят из нейронов ().

Рис. 1.4. Нелинейная модель нейрона
Модель нейрона можно описать парой уравнений
 (1.22)
(1.22)
где Z(t-1) ,...,Z(t-m) - входные сигналы; ω 1 ,...,ω m - синаптические веса нейрона; p - порог; φ(U(t)) - функция активации.
Функция активации бывают трех основных типов :
- функция единичного скачка ;
- кусочно-линейная функция ;
- сигмоидальная функция .
Способ связи нейронов определяет архитектуру нейронной сети . Согласно работе , в зависимости от способа связи нейронов сети делятся на
- однослойные нейронные сети прямого распространения ,
- многослойные нейронные сети прямого распространения ,
- рекуррентные нейронные сети .

Рис. 1.5. Трехслойная нейронная сеть прямого распространения
Таким образом, при помощи нейронных сетей возможно моделирование нелинейной зависимости будущего значения временного ряда от его фактических значений и от значений внешних факторов. Нелинейная зависимость определяется структурой сети и функцией активации.
Пример реализации в MATLAB трехслойной нейронной сети для прогнозирования энергопотребоения на 24 значения вперед можно найти в записи блога Создаем нейронную сеть для прогнозирования временного ряда .
1.3.5. Модели на базе цепей Маркова
Модели прогнозирования на основе цепей Маркова (Markov chain model) предполагают, что будущее состояние процесса зависит только от его текущего состояния и не зависит от предыдущих . В связи с этим процессы, моделируемые цепями Маркова, должны относиться к процессами с короткой памятью.
Пример цепи Маркова для процесса, имеющего три состояния , представлен на .

Рис. 1.6. Цепь Маркова с тремя состояниями
Здесь S 1 ,...,X 3 - состояния процесса Z(t) ; λ 12 S 1 в состояние S 2 , λ 23 - вероятность перехода из состояния S 2 в состояние S 3 и т.д. При построении цепи Маркова определяется множество состояний и вероятности переходов. Есть текущее состояние процесса S i , то качестве будущего состояния процесса выбирается такое состояние S i , вероятность перехода в которое (значение λ ij ) максимальна.
Таким образом, структура цепи Маркова и вероятности перехода состояний определяют зависимость между будущим значением процесса и его текущим значением .
1.3.6. Модели на базе классификационно-регрессионных деревьев
Классификационно-регрессионные деревья (classification and regression trees, CART) являются еще одной популярной структурной моделью прогнозирования временных рядов . Структурные модели CART разработаны для моделирования процессов, на которые оказывают влияние как непрерывные внешние факторы, так и категориальные. Если внешние факторы, влияющие на процесс Z(t) , непрерывны, то используются регрессионные деревья; если факторы категориальные, то - классификационные деревья. В случае, если необходимо учитывать факторы обоих типов, то используются смешанные классификационно-регрессионные деревья.

Рис. 1.7. Бинарное классификационно-регрессионное дерево
Согласно модели CART, прогнозное значение временного ряда зависит от предыдущих значений, а также некоторых независимых переменных. На приведенном на примере сначала предыдущее значение процесса сравнивается с константой Z 0 . Если значение Z(t-1) меньше Z 0 , то выполняется следующая проверка: X(t) > X 11 . Если неравенство не выполняется, то Z(t) = C 3 , иначе проверки продолжаются до того момента, пока не будет найден лист дерева, в котором происходит определение будущего значения процесса Z(t) . Важно, что при определении значения в расчет принимаются как непрерывные переменные, например, X(t) , так и категориальные Y , для которых выполняется проверка присутствия значения в одном из заранее определенных подмножеств. Значения пороговых констант, например, Z 0 , X 11 , а также подмножеств Y 11 ,Y 12 выполняется на этапе обучения дерева .
Таким образом, CART моделирует зависимость будущей величины процесса Z(t) при помощи структуры дерева, а также пороговых констант и подмножеств .
1.1.1. Другие модели и методы прогнозирования
Кроме классов моделей прогнозирования , рассмотренных выше, существуют менее распространенные модели и методы прогнозирования . Главным недостатком моделей и методов , упомянутых в настоящем разделе, является недостаточная методологическая база , т. е. недостаточно подробное описание возможностей как моделей, так и путей определения их параметров. Кроме того, в открытом доступе можно найти лишь небольшое количество статей, посвященных применению данных методов.
Метод опорных векторов (support vector machine, SVM) применяется, например, для прогнозирования движения рынков и цен на электроэнергию . В основу метода положена классификация, производимая за счет перевода исходных временных рядов, представленных в виде векторов, в пространство более высокой размерности и поиска разделяющей гиперплоскости с максимальным зазором в этом пространстве. Алгоритм SVM работает в предположении, что чем больше разница или расстояние между этими параллельными гиперплоскостями, тем меньше будет средняя ошибка классификатора . При этом задача прогнозирования решается таким образом, что на этапе обучения классификатора выявляются независимые переменные (внешние факторы), будущие значения которых определяют в какой из определенных ранее подклассов попадет прогноз Z(t) .
Генетический алгоритм (genetic algorithm, GA) был разработан и часто применяется для решения задач оптимизации, а также поисковых задач. Однако некоторые модификации GA позволяют решать задачи прогнозирования.
Важными являются их простота и прозрачность моделирования. Еще одним достоинством является единообразие анализа и проектирования, заложенное в работе . На сегодняшний день данный класс моделей является одним из наиболее популярных , а потому в открытом доступе легко найти примеры применения авторегрессионных моделей для решения задач прогнозирования временных рядов различных предметных областей.
Недостатками данного класса моделей являются: большое число параметров модели, идентификация которых неоднозначна и ресурсоемка ; низкая адаптивность моделей, а также линейность и, как следствие, отсутствие способности моделирования нелинейных процессов, часто встречающихся на практике .
. Достоинствами данного класса моделей являются простота и единообразие их анализа и проектирования. Данный класс моделей чаще других используется для долгосрочного прогнозирования .
Недостатком данного класса моделей прогнозирования является отсутствие гибкости .
Нейросетевые модели и методы . Основным достоинством нейросетевых моделей является нелинейность, т.е. способность устанавливать нелинейные зависимости между будущими и фактическими значениями процессов. Другими важными достоинствами являются: адаптивность, масштабируемость (параллельная структура ANN ускоряет вычисления) и единообразие их анализа и проектирования .
При этом недостатками ANN являются отсутствие прозрачности моделирования; сложность выбора архитектуры, высокие требования к непротиворечивости обучающей выборки; сложность выбора алгоритма обучения и ресурсоемкость процесса их обучения .
Простота и единообразие анализа и проектирования являются достоинствами моделей на базе цепей Маркова .
Недостатком данных моделей является отсутствие возможности моделирования процессов с длинной памятью .
Модели на базе классификационно-регрессионных деревьев . Достоинствами данного класса моделей являются: масштабируемость, за счет которой возможна быстрая обработка сверхбольших объемов данных; быстрота и однозначность процесса обучения дерева (в отличие от ANN) , а также возможность использовать категориальные внешние факторы.
Недостатками данных моделей являются неоднозначность алгоритма построения структуры дерева; сложность вопроса останова т.е. вопроса о том, когда стоит прекратить дальнейшие ветвления; отсутствие единообразия их анализа и проектирования .
Достоинства и недостатки моделей и методов систематизированы в таблице 1.
Таблица 1. Сравнение моделей и методов прогнозирования
| Модель и метод | Достоинства | Недостатки |
|---|---|---|
| Регрессионные модели и методы | простота, гибкость, прозрачность моделирования; единообразие анализа и проектирования | сложность определения функциональной зависимости; трудоемкость нахождения коэффициентов зависимости; отсутствие возможности моделирования нелинейных процессов (для нелинейной регрессии) |
| Авторегрессионные модели и методы | простота, прозрачность моделирования; единообразие анализа и проектирования; множество примеров применения | трудоемкость и ресурсоемкость идентификации моделей; невозможность моделирования нелинейностей; низкая адаптивность |
| Модели и методы экспоненциального сглаживания | недостаточная гибкость; узкая применимость моделей | |
| Нейросетевые модели и методы | нелинейность моделей; масштабируемость, высокая адаптивность; единообразие анализа и проектирования; множество примеров применения | отсутствие прозрачности; сложность выбора архитектуры; жесткие требования к обучающей выборке; сложность выбора алгоритма обучения; ресурсоемкость процесса обучения |
| Модели и методы на базе цепей Маркова | простота моделирования; единообразие анализа и проектирования | невозможность моделирования процессов с длинной памятью; узкая применимость моделей |
| Модели и методы на базе классификационно-регрессионных деревьев | масштабируемость; быстрота и простота процесса обучения; возможность учитывать категориальные переменные | неоднозначность алгоритма построения дерева; сложность вопроса останова |
Нужно дополнительно отметить, что ни для одной из рассмотренных групп моделей (и методов) в достоинствах не указана точность прогнозирования . Это сделано в связи с тем, что точность прогнозирования того или иного процесса зависит не только от модели , но и от опыта исследователя , от доступности данных , от располагаемой аппаратной мощности и многих других факторов. Точность прогнозирования будет оцениваться для конкретных задач , решаемых в рамках данной работы.
В ряде работ , , указано, что на сегодняшний день наиболее распространенными моделями прогнозирования являются авторегрессионные модели (ARIMAX), а также нейросетевые модели (ANN) . В статье , в частности, утверждается: «Without a doubt ARIMA(X) and GRACH modeling methodologies are the most popular methodologies for forecasting time series. Neural networks are now the biggest challengers to conventional time series forecasting methods» . (Без сомнений модели ARIMA(X) и GARCH являются самыми популярными для прогнозирования временных рядов. В настоящее время главную конкуренцию данным моделям составляют модели на основе ANN .)
1.4.2. Комбинированные модели
Одной из популярных современных тенденций в области создания моделей прогнозирования является создание комбинированных моделей и методов . Подобный подход дает возможность компенсировать недостатки одних моделей при помощи других и направлен на повышение точности прогнозирования, как одного из главных критериев эффективности модели.
Одной из первых работ в этой области является статья . В ней предлагается подход, в котором прогнозирование временного ряда осуществляется в два этапа . На первом этапе на основании моделей распознавания образов (pattern recognition) выделяются гомогенные группы (patterns) временного ряда . На следующем этапе для каждой группы строится отдельная модель прогнозирования . В статье указывается, что при комбинированном подходе удается повысить точность прогнозирования временных рядов .
В работе предлагается модель для прогнозирования цен на электроэнергию Испании. При помощи вейвлет преобразования (wavelet transform) доступные значения временного ряда разделяются на несколько последовательностей, для каждой из которых строится отдельная модель ARIMA.
В обзоре моделей прогнозирования энергопотребления рассматривается следующие типы комбинаций:
- нейронные сети + нечеткая логика ;
- нейронные сети + ARIMA ;
- нейронные сети + регрессия ;
- нейронные сети + GA + нечеткая логика ;
- регрессия + нечеткая логика .
В большинстве комбинаций модели на основе нейронных сетей применяются для решения задачи кластеризации , а далее для каждого кластера строиться отдельная модель прогнозирования на основе ARIMA, GA, нечеткой логики и др. В работе утверждается, что применение комбинированных моделей , выполняющих предварительную кластеризации и последующее прогнозирование внутри определенного кластера, является наиболее перспективным направлением развития моделей прогнозирования .
Работа посвящена вопросам кластеризации временных рядов для того, чтобы на основании полученных кластеров выполнять прогнозирование. Для кластеризации предлагается два метода: метод K- cредних (K-mean) и метод нечетких C-средних (fuzzy C-mean). Целью обоих алгоритмов кластеризации является извлечение полезной информации из временного ряда для последующего прогнозирования. Авторы утверждают, что применение кластеризации дает возможность повысить точность прогнозирования.
Применение комбинированных моделей является направлением, которое при корректном подходе позволяет повысить точность прогнозирования . Главным недостатком комбинированных моделей является сложность и ресурсоемкость их разработки : нужно разработать модели таким образом, чтобы компенсировать недостатки каждой из них, не потеряв достоинств.
Ряд исследователей пошли по альтернативному пути и разработали авторегрессионные модели , в основе которых лежит предположение о том, что временной ряд есть последовательность повторяющихся кластеров (patterns). Однако при этом разработчики не создавали комбинированных моделей, а определяли кластеры и выполняли прогноз на основании одной модели . Рассмотрим эти модели подробнее.
В работе предложена модель прогнозирования направления движения индексов рынка (index movement), учитывающая кластеры временного ряда. Пусть временной ряд содержит три значения -1, 0 и 1, которые характеризуют спад, стабильное состояние и подъем рынка соответственно. Кластером (pattern) называется последовательность для i = 1,2,...,N-M , где N - число доступных отчетов временного ряда Z(t) . Для определения прогнозного значения рассмотрена последняя доступная информация, а именно последовательность Z(N,M) = Z(N-M+1),Z(N-M+2),...,Z(N) , для которой определена ближайшая похожая (closet match) Z(Q,M) = Z(Q+1),Z(Q+2),...,Z(Q+M) . При этом функция, определяющая близость, имеет вид
т.е. близость кластеров определяется простым сравнением. Далее вычисляется прогнозное значение
Таким образом, в данной модели предполагается, что если в некоторый момент времени в прошлом рынок вел себя определенным образом, то в будущем его поведение повторится в связи с тем, что временной ряд является последовательностью кластеров.
Еще в двух работах , предложена модель прогнозирования, основанная на модели авторегрессии, но принимающая во внимание кусочки временного ряда . Здесь прогнозное значение временного ряда определено выражением
которое является линейной авторегрессией порядка M . При этом коэффициенты авторегрессии α 0 ,α 1 ,…,α M определяются следующим образом. Предполагается, что существует K кусочков (векторов) длины M временного ряда, для которых выполняется выражение
 (1.28)
(1.28)
При определении ближайших векторов (closest vectors) Z(i 1 -1) ,Z(i 1 -2) ,…,Z(i 1 -M) ,...,Z(i K -1) ,Z(i K -2) ,…,Z(i K -M) в статье использовано значение линейной корреляции Пирсона между всеми возможными векторами и новейшим вектором (last available vector) Z(t-1) , а также, , является перспективным в области создания моделей прогнозирования временных рядов . Предложенная в диссертации модель прогнозирования развивает модели , , и устраняет все перечисленные выше недостатки: модель позволяет учитывать влияния внешних факторов; формулируется критерий определения похожей выборки для двух видов постановок задачи прогнозирования (); количество параметром модели сокращается до одного, что существенно упрощает идентификацию модели.
1.5. Выводы
1) Задача прогнозирования временных рядов имеет высокую актуальность для многих предметных областей и является неотъемлемой частью повседневной работы многих компаний.
2) Установлено, что к настоящему времени разработано множество моделей для решения задачи прогнозирования временного ряда , среди которых наибольшую применимость имеют авторегрессионные и нейросетевые модели .
3) Выявлены достоинства и недостатки рассмотренных моделей . Установлено, что существенным недостатком авторегрессионных моделей является большое число свободных параметров, требующих идентификации; недостатками нейросетевых моделей является ее непрозрачность моделирования и сложность обучения сети.
4) Определено, что наиболее перспективным направлением развития моделей прогнозирования с целью повышения точности является создание комбинированных моделей , выполняющих на первом этапе кластеризацию, а затем прогнозирование временного ряда внутри установленного кластера.
Методы прогнозирования временных рядов
1. Прогнозирование как задача анализа временного ряда. Детерминированная и случайная составляющие: способы их выделения и оценки.
Прогнозирование – это научное выявление вероятностных путей и результатов предстоящего развития явлений и процессов, оценка показателей процессов для более или менее отдаленного будущего.
Изменение состояния наблюдаемого явления (процесса) характеризуется совокупностью параметров x1, x2, … , xt,…, измеренных в последовательные моменты времени. Такая последовательность называется временным рядом.
Анализ временных рядов – одно из направлений науки прогнозирования.
Если одновременно рассматриваются несколько характеристик процесса, то в этом случае говорят о многомерных временных рядах.
Под детерминированной (закономерной) составляющей временного ряда x1, x2, … , xn понимается числовая последовательность d1, d2, … , dn, элементы которой вычисляются по определенному правилу как функция времени t.
Если исключить из ряда детерминированную составляющую, то оставшаяся часть будет выглядеть хаотично. Ее называют случайной компонентой ε1, ε2, … , εn.
Модели разложения временного ряда на детерминированную и случайную компоненты:
1. Аддитивная модель:
xt = dt + εt, t=1,…n
2. Мультипликативная модель:
xt = dt · εt, t=1,…n
Если мультипликативную модель прологарифмировать, то получим аддитивную модель для логарифмов xt.
В детерминированной компоненте выделяют:
1) Тренд (trt) – плавно изменяющаяся нециклическая компонента, описывающая чистое влияние долговременных факторов, эффект которых сказывается постепенно.
2) Сезонная компонента (St) – отражает повторяемость процессов во времени.
3) Циклическая компонента (Ct) – описывает длительные периоды относительного подъема и спада.
4) Интервенция – существенное кратковременное воздействие на временной ряд.
Модели тренда:
– линейная: trt = b0 + b1t
– нелинейные модели:
полиномиальная: trt = b0 + b1t + b2t2 + … + bntn
логарифмическая: trt = b0 + b1 ln(t)
логистическая:
экспоненциальная: trt = b0 · b1t
параболическая: trt = b0 + b1t + b2t2
гиперболическая: trt = b0 + b1 /t
Тренд используется для долгосрочного прогноза.
Выделение тренда:
1) Метод наименьших квадратов (время – фактор, временной ряд – зависимая переменная):
xti = f (ti, θ)+εt i=1,…n
f – функция тренда;
θ – неизвестные параметры модели временного ряда.
εt – независимые и одинаково распределенные случайные величины.
Если минимизировать функцию, можно найти параметры θ.
2) Применение разностных операторов
![]()
Выделение сезонных эффектов
Пусть m – число периодов, p – величина периода.
St = St+p, для любых t.
1) Оценка сезонной компоненты
а) Сезонные эффекты на фоне тренда
Для аддитивной модели xt = trt + St + εt оценка:
Если необходимо, чтобы сумма сезонных эффектов равнялась 0, то переходят к скорректированным оценкам сезонных эффектов:

Для мультипликативной модели xt = trt * St * εt:

б) При наличии в ряде циклической компоненты (метод скользящих средних)
Идея метода: каждое значение исходного ВР заменяется средним значением на интервале времени, длина которого выбирается заранее. Выбранный интервал как бы скользит вдоль ряда.
Скользящее среднее при медианном сглаживании: t=med (xt-m,xt-m+1, …,xt+m)
При средне арифметическом сглаживании:
xt=1/(2m+1)(xt-m+xt-m+1+…+xt+m), если р – четный,
xt=1/(2m)(1/2*xt-m+xt-m+1+…+1/2*xt+m) если р – нечетный.
Для аддитивной модели xt = trt +Ct + St + εt.
Для упрощения обозначений: начнем нумерацию величин с единицы, изменим нумерацию исходного ряда так, чтобы величине x соответствовал член xt.
– скользящее среднее с периодом p, построенное по xt.
Для мультипликативной модели – перейти к логарифмам и получить мультипликативную модель.
xt = trt · Ct · St · εt
yt = log xt, dt = log trt, gt = log Ct, rt = log St, δt = log εt
yt = dt + gt + rt + δt
2) Удаление сезонной компоненты (сезонное выравнивание)
а) При наличии оценок сезонной компоненты:
Для аддитивной модели – путем вычитания из начальных значений ряда полученных сезонных оценок .
Для мультипликативной модели – путем деления начальных значений ряда на соответствующие сезонные оценки и умножением на 100%.
б) Применение разностных операторов
где В – оператор сдвига назад.
Разностный оператор второго порядка:
Если ВР одновременно содержит тренд и сезонную компоненту, то их удаление возможно с помощью последовательного применения простых и сезонных разностных операторов. Порядок их применения не существенен:
3) Прогнозирование с помощью сезонной компоненты:
Для аддитивной модели:
![]()
Для мультипликативной модели:

2. Модели временного ряда: AR(p), MA(q), ARIMA(p,d,q). Идентификация моделей, оценка параметров, исследование адекватности модели, прогнозирование.
Для описания вероятностной компоненты временного ряда используют понятие случайного процесса.
Случайным процессом x(t), заданным на множестве Т, называют функцию от t, значения которой при каждом t T являются случайной величиной.
Случайные процессы, у которых вероятностные свойства не изменяются во времени, называются стационарными (матожидание и дисперсия – константы).
В качестве модели стационарных временных рядов чаще всего используются:
Скользящее среднее;
Их комбинации.
Для проверки стационарности ряда остатков и оценки его дисперсии используют:
Выборочную автокорреляционную функцию (коррелограмму);
Частную автокорреляционную функцию.
Пусть εt – процесс белого шума, т.е. в разные моменты времени t случайные величины εt независимы и одинаково распределены с параметрами M(εt)=0, D(εt)=σ2=const. Тогда:
Случайный процесс x(t) со средним значением μ называется процессом авторегрессии порядка p (AR(p)), если для него выполняется соотношение:
x(t)-μ= α1 (x(t-1) – μ) + α2 (x(t-2) – μ) +…+ αp (x(t-p) – μ) + εt
Случайный процесс x(t) называется процессом скользящего среднего порядка q (MA(q)), если для него выполняется соотношение:
x(t)= εt + β1 εt-1 +…+ βq εt-q
Случайный процесс x(t) называется процессом авторегрессии-скользящего среднего порядков p и q (ARMA(p,q)), если для него выполняется соотношение:
Нестационарные технические и экономические процессы могут быть описаны модифицированной моделью ARMA(p,q). Для удаления тренда можно использовать разностные операторы.
Пусть даны две последовательности U=(…,U-1,U0,U1,…) и V=(…,V-1, V0,V1,V2,…) такие, что:
Означает ,для
![]() означает и т.д.
означает и т.д.
Тогда процесс AR(p) представляется в виде ,
MA(q): ![]() ,
,
ARMA(p,q): ![]()
B можно использовать как разностный оператор, т.е. ![]()
эквивалентно V=(1-B)U
Для разностей второго порядка:
z =(1-B)V=(1-B)2U

где – разностный оператор порядка d; x=(1-B)dx.
Идентифицировать модель – определить ее параметры p, d и q. Для идентификации модели служат графики частных автокорреляционных (АКФ) и частных автокорреляционных функций (ЧАКФ).
АКФ. k-й член АКФ определяется по формуле:
 (*)
(*)
Параметр k называют лагом. На практике k < n/4. График АКФ – коррелограмма. Если полученный ряд остатков нестационарный, то по коррелограмма можно определить причины нестационарности.
Значения ЧАКФ akk находят, решая систему Юла – Уолкера, используя значения АКФ
Система Юла – Уолкера:
R1 = a1 + a2*r1 + … + ap*rp-1
r2 = a1*r1 + a2 + … + ap*rp-2
………………………………..
rp = a1*rp-1 + a2*rp-2 + …+ ap
После визуализации ряда и удаления тренда рассматривается АКФ. Если график АКФ не имеет тенденции к затуханию, то это нестационарный процесс (модель ARIMA). При наличии сезонных колебаний коррелограмма содержит периодические всплески, как правило, соответствующие периоду колебаний. Рассматриваются разности 1-го, 2-го,…k-го порядка, пока ряд не станет стационарным, тогда параметр d=k (обычно k не больше 2). Переходят к идентификации стационарной модели.
Идентификация стационарных моделей:
АКФ плавно спадает;
ЧАКФ обрывается на лаге p.
АКФ обрывается на лаге q.
ЧАКФ плавно спадает.
Оценка параметров m, ai модели AR(p):
В качестве оценки m можно взять среднее значении ВР
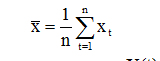
Для оценки ai найдем корреляцию между X(t) и X(t-k):
Общее решение этого уравнения относительно rk определяется корнями характеристического уравнения
Пусть корни характеристического уравнения различны. Тогда общее решение может быть записано в виде:
Из требования стационарности следует, что все |λi|<1.
Если записать уравнение (**) для k=1, 2, 3…., получим систему Юла-Уоркера для AR(p) процесса:
r1 = a1 +a2*r1 + … + ap*rp-1
r2 = a1*r1 + a2 + … + ap*rp-2
………………………………..
rp = a1*rp-1 + a2*rp-2 + …+ap
Решая эту систему относительно a1, a2....ap, получим параметры AR(p).
Оценка параметра βi модели MA(q):
Для процесса МА(q) при |k| > q Cov = 0.
Cov = s2*(bk + b1*bk+1 + b2*bk+2 + … + bq-k*bq)
Отсюда автокорреляционная функция имеет вид:
 (***)
(***)
Для оценивания коэффициентов bi по наблюденному участку траектории существует несколько путей. Наиболее простой:
Находят
коэффициенты корреляции ![]() по формуле (*). Из
системы (***) получают систему нелинейных уравнений для нахождения bi. Она решается
итерационными методами.
по формуле (*). Из
системы (***) получают систему нелинейных уравнений для нахождения bi. Она решается
итерационными методами.
Прогнозирование. При прогнозировании необходимо получить детерминированные значения ВР по уже имеющимся формулам, а затем рассчитать случайные значения по подобранной модели и скорректировать детерминированные значения на величину случайных значений.
3. Прогнозирование с помощью искусственных нейронных сетей, метод окон.
Решение математических задач с помощью нейронных сетей (НС) осуществляется путем обучение НС способам решения этих задач.
Обучение многослойной нейронной сети производится методом обратного распространения ошибки (Back Propagation).
Модель искусственного нейрона

где xi – входные сигналы,
ai – коэффициенты проводимости (const), которые корректируются в процессе обучения,
F – функция активации, она нелинейная, в разных моделях может называться по-разному. Например, «сигмоида»:
Общая структура нейронной сети:

Скрытых слоев может быть несколько, поэтому НС – многослойная.
– вектор эталонных сигналов (желаемых)
yi – вектор реальных (выходных) сигналов
xi – вектор входных сигналов.
Стратегия обучения «обучение с учителем»
Типовые шаги:
1) Выбрать очередную обучающую пару из обучающего множества .
x – входной вектор;
– соответствующий ему желаемый (выходной вектор).
Подать входной вектор х на вход НС.
2) Вычислить выход сети у – реальный выходной сигнал.
Предварительно, весовые коэффициенты aij и bij задаются произвольно случайным образом.
3) Вычислить отклонение (ошибку): ![]()
4) Подкорректировать веса aij и bij сети так, чтобы минимизировать ошибку.
![]()
5) Повторить шаги 1– 4.
Процесс повторяется до тех пор, пока ошибка на всем обучающем множестве не уменьшится до требуемой величины.
Проход вперед сигнала X по сети:
Из обучающего множества берется пара. Для каждого слоя, начиная с первого, вычисляется Y: Y = F(X·A),
где A – матрица весов слоя;
F – функция активации.
Вычисления – слой за слоем.
Обратный проход ошибки по НС:
Выполняется подстройка весов выходного слоя. Для этого применяется модифицируемое дельта-правило.
Рис. Обучение одного веса от нейрона p в скрытом слое j к нейрону q в выходном слое k
Для выходного нейрона сначала находится сигнал ошибки
![]()
εq умножается на производную сжимающей функции , вычисленную для этого нейрона слоя k. Получаем величину δ:
Δapqk = α · δqk · ypj,
где α – коэффициент скорости обучения (0.01≤ α <1) – const, подбирается экспериментально в процесса обучения.
ypj – выходной сигнал нейрона p слоя j.
 – величина веса в
связке нейронов p→q на шаге t (до
коррекции) и шаге t+1 (после коррекции).
– величина веса в
связке нейронов p→q на шаге t (до
коррекции) и шаге t+1 (после коррекции).
Подстройка весов скрытого слоя.
Рассмотрим нейрон скрытого слоя p. При переходе вперед этот нейрон передает свой выходной сигнал нейронам выходного слоя через соединяющие их веса. Во время обучения эти веса функционируют в обратном порядке, пропуская величину δ от выхода назад к скрытому слою.

И так для каждой пары. Процесс заканчивается, если для каждого X НС будет вырабатывать
Прогнозирование с помощью НС. Метод окон.
Задан временной ряд xt, t=1,2…T. Задача прогнозирования сводится к задаче распознавания образов на НС.
Метод выявления закономерности во временном ряде на основе НС называется “windowing” (метод окон).
Используется два окна Wi (input) и Wo (output) фиксированного размера n и m соответственно, для наблюдаемого множества данных.

Эти окна способны перемещаться с некоторым шагом S по кривой (ряду) вдоль оси времени. В результате получается некоторая последовательность наблюдений:
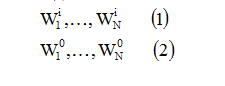
Первое окно Wi, сканирует данные, предает их на вход НС, а Wo – на выход. Получающаяся на каждом шаге пара Wji→Wj0, j=1..n образует обучающую пару (наблюдение). После обучения НС можно использовать для прогноза.
Временные ряды реализуют широкий набор методов описания, построения моделей, декомпозиции и прогнозирования временных рядов как во временной, так и в частотной области. Все процедуры полностью интегрированы и результаты анализа одной модели. Имеются самые разнообразные возможности для просмотра и графического представления одномерных и многомерных рядов. Можно анализировать очень длинные ряды (более 100 тыс. наблюдений для компьютера с 8 Mb оперативной памяти). С многомерными рядами (в случае многомерных исходных данных или с рядами, полученными на различных этапах анализа) можно работать в активной рабочей области; здесь их можно просматривать и сопоставлять друг с другом. Информация о последовательных преобразованиях хранится в виде длинных меток переменных, поэтому при сохранении вновь полученных рядов в файле данных автоматически сохраняется вся "история" каждого из рядов.
С помощью различных преобразований исходного временного ряда можно понять его структуру и имеющиеся в нем закономерности; реализованы такие часто используемые преобразования, как: удаление тренда, удаление автокорреляций, сглаживание скользящими средними (невзвешенными или взвешенными - с весами, заданными пользователем или вычисленными по методам Даниеля, Тьюки, Хэмминга, Парзена и Бартлета), медианное сглаживание (среднее заменено медианой), простое экспоненциальное сглаживание (подробное описание его вариантов см. далее), взятие разностей, суммирование, вычисление остатков, сдвиг, 4253H-сглаживание, косинус-сглаживание, преобразование Фурье, а также обратное преобразование Фурье и др. Можно выполнить анализ автокорреляций, частных автокорреляций и кросскорреляций.
Временные ряды включают полную реализацию модели авторегрессии и проинтегрированного скользящего среднего. Модель может включать константу. Перед построением модели ряд может быть подвергнут преобразованию, которое автоматически будет отменено после построения прогноза по АРПСС, при этом предсказанные значения и их стандартные ошибки будут выражены через значения исходного (а не преобразованного) ряда. Могут быть вычислены приближенные и точные суммы квадратов из условия максимума правдоподобия; уникальной особенностью является способность анализировать модели с длинными периодами сезонности (с лагом до 30).
Стандартный набор результатов содержит оценки параметров, стандартные ошибки и корреляции. Предсказанные значения могут быть представлены в числовой и графической форме и добавлены к исходному ряду. Имеются многочисленные дополнительные функции для исследования остатков, в том числе большой набор графических средств. Реализация модели позволяет проводить анализ прерванных временных рядов (рядов с интервенциями). Имеется возможность использовать одновременно несколько различных интервенций (до 6). Доступны следующие виды интервенций: однопараметрические скачкообразные, двупараметрические постепенные, временные (характер воздействия можно просмотреть на графике). Для всех прерванных моделей могут быть построены прогнозы, которые можно вывести на график (вместе с исходным рядом) и, если требуется, добавить прогнозы к исходному ряду.
Полностью реализованы все 12 классических моделей экспоненциального сглаживания. Задание модели может включать аддитивную или мультипликативную сезонную составляющую и/или линейный, экспоненциальный или демпфированый тренд; в частности, доступны популярные модели с линейным трендом Холта-Винтера. Пользователь может задавать начальное значение параметров сглаживания, начальное значение тренда и (если требуется) сезонные факторы. Для тренда и сезонной составляющей могут быть заданы независимые параметры сглаживания. Для определения лучшей комбинации параметров используется метод поиска на сетке; в таблицах результатов для всех комбинаций значений параметров сглаживания вычисляется средняя ошибка, средняя абсолютная ошибка, сумма квадратов ошибок, среднеквадратическая ошибка, средняя относительная ошибка и средняя абсолютная относительная ошибка. Наименьшие значения этих ошибок выделяются цветом. Имеется возможность автоматического поиска лучшего набора параметров в смысле среднеквадратической, средней абсолютной или средней абсолютной относительной ошибки (для этого используется общая процедура минимизации). Все результаты преобразования экспоненциальным сглаживанием, остатки и прогноз на требуемое число шагов доступны для дальнейшего анализа и вывода на график. Для оценки адекватности модели используются графики, на которых вместе с исходным рядом в подходящем масштабе по оси Y изображаются его сглаженный вариант, прогноз и ряд остатков.
Имеется возможность задать произвольный сезонный лаг и выбрать либо аддитивную, либо мультипликативную сезонную модель. Программа вычисляет скользящие средние, отношения или разности, сезонные компоненты, ряд с сезонной поправкой, сглаженную тренд-циклическую и нерегулярную компоненты. Все эти составляющие ряда доступны для дальнейшего анализа; например, для проверки адекватности можно построить гистограммы, графики на нормальной вероятностной бумаге и т.д.
Структура всех функций и диалоговых окон соответствует требованиям и соглашениям, описанным в документации Bureau of the Census. Можно выбрать либо аддитивные, либо мультипликативные модели. Пользователь может дополнительно вычислить априорные поправки на число рабочих дней и сезонные поправки. Колебания числа рабочих дней оцениваются регрессионными методами (с правильной обработкой крайних членов ряда) и затем (по желанию) используются для корректировки ряда. Реализованы стандартные средства для градуировки выбросов, вычисления сезонных факторов и вычисления тренд-циклической компоненты (имеется возможность выбирать несколько типов взвешенного скользящего среднего; кроме того, программа может сама находить оптимальную длину и тип скользящего среднего). Итоговые компоненты ряда (сезонная, тренд-циклическая, нерегулярная) и ряд с внесенной сезонной поправкой всегда доступны для дальнейшего анализа и вывода на график; кроме того, все они могут быть сохранены для дальнейшего исследования другими методами и/или в других программах. Все компоненты выводятся на графики в различной форме, включая категоризованные графики по месяцам (кварталам).
С помощью реализованных методов полиномиальных распределенных лагов можно выполнять оценку моделей с обычными лагами и лагами Алмона. Для анализа распределений переменных модели имеется ряд графических средств.
Преимущества реализации спектрального анализа в STATISTICA особенно отчетливо проявляются при анализе очень длинных временных рядов (с более чем 250 тыс. наблюдений) и не предполагают каких-либо ограничений на длину ряда (в частности, длина исходного ряда не обязана быть четной). Вместе с тем, иногда бывает разумно предварительно увеличить или уменьшить длину ряда. Стандартные методы предварительной обработки ряда включают косинус-сглаживание, вычитание среднего и удаление тренда. Результаты обычного спектрального анализа содержат коэффициенты частоты, периода, коэфициенты при синусах и косинусах, периодограмма и оценка спектральной плотности. Оценка плотности может быть вычислена с помощью весов Даниеля, Хэмминга, Бартлетта, Тьюки, Парзена или с весами и шириной, заданными пользователем. Очень полезно, особенно при работе с длинными рядами, иметь возможность выводить в убывающем порядке заранее заданное число точек периодограммы или спектральной плотности; таким образом можно легко обнаружить резкие пики периодограммы и спектральной плотности для длинных рядов.
Имеется возможность вычислить d-критерий Колмогорова-Смирнова для значений периодограммы чтобы проверить, подчиняются ли они экспоненциальному распределению (является ряд белым шумом или нет). Для представления результатов анализа имеются различные типы графиков; можно отобразить коэффициенты при синусах и косинусах, периодограмму, лог- периодограмму, спектральную и лог-спектральную плотность по отношению к частотам, периодам и лог-периодам. В случае длинного исходного ряда имеется возможность выбрать конкретный сегмент (период), для которого будут изображаться соответствующие периодограмма и график спектральной плотности, тем самым будет улучшено их "разрешение".
При кросс-спектральном анализе, в дополнение к результатам обычного спектрального анализа каждого отдельного ряда, вычисляется кросс- периодограмма (вещественная и мнимая часть), ко-спектральная плотность, квадратурный спектр, кросс-амплитуда, значения когерентности, усиления и фазовый спектр. Все эти величины могут быть выведены на график, где по горизонтальной оси будет откладываться частота, период или лог-период либо для всего интервала периодов (соответственно, частот), либо для выбранного пользователем диапазона. Указанное пользователем количество наибольших значений кросс-периодограммы (вещественных или мнимых) может быть выведено в убывающем порядке в виде таблицы результатов, что позволяет легко выявлять на ней резкие пики для длинных исходных рядов. Как и во всех других процедурах модуля Временные ряды, все полученные ряды могут быть добавлены в активную рабочую область и затем подвергнуты дальнейшему исследованию с помощью других методов анализа временных рядов или средствами других модулей системы STATISTICA.
Наконец, в системе STATISTICA реализованы регрессионные методы анализа временных рядов для переменных с запаздыванием (лагом) или без него, в том числе - регрессия, проходящая через начало координат, нелинейная регрессия и интерактивное "что-если" прогнозирование.
Транскрипт
1 Лабораторная работа 10. Прогнозирование временных рядов. Цель работы: Построение прогноза временного ряда несколькими способами и выбор лучшей модели прогнозирования. Нужно сделать Взять 2 временных ряда -- один в виде отдельного файла, другой из документа Excel Провести корреляционный анализ каждого временного ряда построить его график, рассчитать АКФ, построить график АКФ, определить свойства ряда Построить прогнозы заданных временных рядов несколькими различными способами. Модели временных рядов выбирать из текста лекции. Оценить ошибки прогнозирования и на основании рассчитанных ошибок выбрать наилучшую модель прогнозирования. К отчету Документ Mathematica с отчетами. Анализ и прогнозирование временных рядов Введение Прогнозирование одна из самых востребованных задач бизнес-аналитики. Продажи, поставки, заказы это процессы, распределенные во времени, следовательно, прогнозирование в области продаж, сбыта и спроса, управления материальными запасами и потоками обычно связано именно с анализом временных рядов. Временной ряд последовательность наблюдений за изменениями во времени значений параметров некоторого объекта или процесса. Временные отсчеты значения, зафиксированные в некоторые, обычно равноотстоящие моменты времени. В задачах анализа временных рядов мы имеем дело с дискретным временем, когда каждое наблюдение за параметром образует временной отсчет. Все временные отсчеты нумеруются в порядке возрастания. Тогда временной ряд будет представлен в виде X={x 1,x 2,x n }. Одномерные временные ряды содержат наблюдения за изменением только одного параметра исследуемого процесса или объекта, а многомерные за двумя параметрами или более. Например, трехмерный временной ряд, содержащий наблюдения за тремя параметрами X,Y,Z процесса F можно записать в следующем виде Цели и задачи анализа временных рядов F={(x 1,y 1,z 1), (x 2,y 2,z 2),(x n,y n,z n)} Описание характеристик и закономерностей ряда Моделирование построение модели исследуемого процесса Прогнозирование предсказание будущих значений временного ряда
2 Управление. Зная свойства временных рядов, можно выработать воздействия на соответствующие бизнес-процессы для управления ими методы Детерминированная и случайная составляющая временного ряда Закономерная (детерминированная) составляющая временного ряда последовательность значений, элементы которой могут быть вычислены в соответствии с определенной функцией. Закономерная составляющая временного ряда отражает действие известных факторов и величин. Зная функцию, описывающую закономерность, в соответствии с которой развивается исследуемый процесс, мы можем вычислить значение детерминированной составляющей в любой момент времени. Случайная (стохастическая) составляющая временного ряда последовательность значений, которая является результатом воздействия на исследуемый процесс случайных факторов. Случайная составляющая и ее влияние на временной ряд могут быть оценены только с помощью статистических методов. Случайная составляющая проявляется как результат воздействия набора случайных факторов на исследуемый процесс и обычно выражается в повышенной изменчивости временного ряда, а также в отклонении значений детерминированной составляющей. Результирующее значение временного ряда это результат взаимодействия детерминированной и случайной составляющих. Простейший вид такого взаимодействия случай, когда, каждое значение временного ряда можно рассматривать как сумму (разность) двух значений, одно из которых обусловлено детерминированной составляющей, а другое случайной, т.е. x i =d i +p i. Модели временных рядов Наблюдаемые значения временного ряда представляют собой результат взаимодействия детерминированной и случайной составляющих. Различают два вида такого взаимодействия: Аддитивное значения временного ряда получаются как результат сложения детерминированной и случайной составляющих Мультипликативное значения временного ряда получаются как результат умножения детерминированной и случайной составляющих Соответственно, аддитивная модель имеет вид x i =d i +p i, мультипликативная модель имеет вид x i =d i p i. Компоненты временного ряда Типовые структуры, которые можно выделить во временном ряду тренд, сезонная компонента, циклическая компонента. Тогда детерминированная составляющая может быть записана в виде: d i =t i +s i +c i, где t i тренд, s i сезонная компонента, c i циклическая компонента.
3 Тренд Тренд медленно меняющаяся компонента временного ряд, которая описывает влияние на временной ряд долговременно действующих факторов, вызывающих плавные и длительные изменения ряда. Чтобы представить характер тренда, обычно достаточно взглянуть на график временного ряда. Наиболее популярные модели для описания тренда: Простая линейная модель: t i =a+b i Полиномиальная модель: t i =a+b 1 i+ b 2 i b n i n. В большинстве реальных задач степень полинома не превышает 5 Экспоненциальная модель: t i =exp(a+b i). Используется в случаях, когда процесс характеризуется равномерным увеличением темпов роста Логистическая модель t i =a./(1+b e - k i), где k константа, управляющая крутизной логистической функции. Такого типа кривые, имеющие S-образную форму, часто называют сигмоидами. Они хорошо описывают процессы с непостоянными темпами роста. Сезонная компонента Многим процессам свойственна повторяемость во времени, причем периодичность таких повторений может изменяться в очень широком диапазоне. Очевидно, что для описания таких периодических изменений, присутствующих во временных рядах, тренд непригоден. Сезонная компонента составляющая временного ряда, описывающая регулярные изменения его значений в пределах некоторого периода и представляющая сосбой последовательность почти повторяющихся циклов. Сезонная компонента может быть привязана к определенному календарному временному интервалу: дню, неделе, месяцу либо к какому-либо событию, которое пямо не соотносится с конкретными календарными интервалами. Сезонную компоненту с изменяющимся периодом иногда называют плавающей. Циклическая компонента Часто временные ряды содержат изменения, слишком плавные и заметные для случайной составляющей. В то же время такие изменения нельзя отнести ни к тренду, поскольку они не являются достаточно протяженными, ни к сезонной компоненте, поскольку они не являются регулярными. Подобные изменения называются циклической компонентой временного ряда. Циклическая компонента временного ряда интервалы подъема или спада, которые имеют различную протяженность, а также различную амплитуду расположенных в них значений. Изучение циклической компоненты часто оказывается полезным для прогнозирования, особенно краткосрочного.
4 Т.о., временной ряд можно представить как композицию, состоящую из двух составляющих случайной и детерминированной. Детерминированная составляющая, в свою очередь, содержит три компоненты тренд, сезонную и циклическую. Исследование временных рядов и автокорреляция Цель анализа временного ряда построение его математической модели, с помощью которой можно обнаружить закономерности поведения ряда, а также построить прогноз его дальнейшего развития. Временной ряд называется стационарным, если его статистические свойства (мат.ожидание и дисперсия) одинаковы на всем протяжении ряда. В противном случае ряд называется нестационарным. Прежде чем приступить к построению модели ряда, его стараются привести к стационарному. При исследовании временного ряда ищут ответы на несколько вопросов. Является ли ряд случайным? Содержит ля временной ряд тренд и сезонную компоненту? Является ли временной ряд стационарным? Для ответа используется аппарат корреляционного анализа. Корреляция характеризует степень статистической взаимосвязи между элементами данных. Если взаимосвязь между элементами присутствует, то данные называются коррелированными. Когда определяется степень статистической взаимосвязи между значениями одного временного ряда, имеет место автокорреляция. В этом случае вычисляется корреляция между временным рядом и его копией, сдвинутой на один или несколько временных отсчетов. Смысл корреляционного анализа заключается в следующем. Детерминированная составляющая характеризуется плавными изменениями значений ряда, т.е. соседние значения ряда не должны сильно отличаться, и, следовательно, между ними присутствует сильная зависимость. Если значения ряда в большей степени обусловлены случайной составляющей и соседние значения могут существенно отличаться друг от друга, то корреляция будет меньше. Пример. Пусть дан ряд, который содержит последовательность ежемесячных наблюдений за продажами. Месяц Продажи Январь 125 Февраль 130 Март 140 Апрель 132 Май 145 Июнь 150 Июль 148 Август 155 Сентябрь 157 Октябрь 160 Ноябрь 158 Декабрь 165
5 Для того, чтобы вычислить автокорреляцию ряда, будем использовать его копию, сдвинутую в сторону запаздывания на определенное количество отсчетов. X X i X i X i-n 125 Для определения степени взаимной зависимости элементов ряда используется коэффициент автокорреляции r k, где k количество отсчетов, на которое был сдвинут временной ряд при вычислении данного коэффициента. r k = n i= k+ 1 (x i x)(x (n k) σ i k 2 x x) где x i значение i-го отсчета, x i-k наблюдение x i со сдвигом на k временных отсчетов, x - - среднее значение ряда, σ -- дисперсия ряда. 2 x Коэффициент корреляции изменяется в диапазоне [-1,1], где r k =1 указывает на полную корреляцию Если рассчитать коэффициенты корреляции для каждого сдвига, получим последовательность коэффициентов, называемую автокорреляционной функцией (АКФ). Результаты расчета АКФ для ряда X. k r k Автокорреляционная функция временного ряда Значение коэффициента автокорреляции при нулевом сдвиге равно 1, поскольку ряд полностью коррелирован с самим собой. Также наблюдается высокая степень корреляции r k >0.8 при сдвиге менее чем на 4 временных отсчета и умеренная при r k для 5-7 отсчетов. Затем корреляция быстро падает. Т.о., можно сделать вывод о высокой степени зависимости между соседними значениями данного временного ряда. Данный вывод подтверждается визуальным исследованием ряда: в нем присутствует небольшой линейный положительный тренд, отсутствует сезонная компонента, а достаточно высокая гладкость позволяет выдвинуть предположение о малой величине случайной


6 составляющей. Все это хорошо согласуется с выводами, сделанными на основе корреляционного анализа. Для произвольного временного ряда, корреляционный анализ позволяет придти к следующим заключениям: Если ряд содержит тренд, то коэффициент автокорреляции значителен для первых нескольких сдвигов ряда, а в дальнейшем убывает до нуля Если действие случайной компоненты велико, то коэффициенты автокорреляции для любого значения сдвига будут близки к нулю. Случайный ряд и его АКФ Если ряд содержит сезонную компоненту, то коэффициент автокорреляции будет большим для значений сдвига, равных периоду сезонной составляющей или кратных ему. Ряд с сезонной компонентой и его АКФ
7 Таким образом, корреляционный анализ позволяет выявить в ряду тренд и сезонную компоненту, а также определять, насколько поведение ряда обусловлено его случайной компонентой. Знание данных свойств временного ряда помогает строить более адекватные модели и выбирать методы прогнозирования Модели прогнозирования Главный инструмент прогнозирования в современной бизнес-аналитике прогностические модели. Обобщенная модель прогноза Набор входных переменных x i (i=1,n) исходные данные для прогноза. Набор выходных переменных y j (j=1,m) набор прогнозируемых величин, n>m. Когда решается задача прогнозирования временного ряда, описывающего динамику изменения некоторого бизнес-процесса, входные значения наблюдения за развитием процесса в прошлом, а выходные прогнозируемые значения процесса в будущем. При этом временные интервала прошлых наблюдений и временные интервалы, по которым требуется получить прогноз, должны соответствовать друг другу. «Наивная» модель прогнозирования Предполагает, что последний период прогнозируемого временного ряда лучше всего описывает будущее этого ряда. Простейшая модель y(t+1)=x(t), где x(t) последнее наблюдаемое значение, y(t+1) прогноз. Чтобы модель учитывала наличие возможных трендов, ее можно несколько усложнить, например преобразовав к виду y(t+1)=x(t)+ или y(t+1)=x(t). При необходимости учета сезонных колебаний модель модифицируется следующим образом: y(t+1)=x(t-s), где s показатель, учитывающий сезонные изменения прогнозируемого временного ряда. Экстраполяция Если значения функции f(x) известны в некотором интервале , то целью экстраполяции является определение наиболее вероятного значения в точке x n+1. Экстраполяция применима только в тех случаях, когда функция f(x), а соответственно и описываемый ей временной ряд, достаточно стабильна и не подвержена резким изменениям.
8 Наиболее популярный метод экстраполяции в настоящее время экспоненциальное сглаживание. Основной его принцип заключается в том, чтобы учесть в прогнозе все наблюдения, но с экспоненциально убывающими весами. Метод позволяет принять во внимание сезонные колебания ряда и предсказать поведение трендовой составляющей. Например, в случае ряда с «нулевым» трендом, можно выбрать следующую модель экспоненциального сглаживания y(t+1)= λ y(t)+(1-λ) x(t), \где x(t) последнее наблюдаемое значение, y(t) прогноз на момент времени t, y(t+1) прогноз на момент времени t+1. 0< λ<1 параметр сглаживания или параметр адаптации, характеризующий меру обесценивания наблюдения за единицу времени. Инструментом прогноза является модель, первоначальная оценка параметра λ производится по нескольким первым наблюдениям. На ее основе делается прогноз, который сравнивается с фактическими наблюдениями. Далее модель корректируется в соответствии с величиной ошибки прогноза и вновь используется для прогнозирования следующего уровня, вплоть до исчерпания всех наблюдений. Таким образом, она постоянно «впитывает» новую информацию, приспосабливается к ней, и к концу периода наблюдения отображает тенденцию, сложившуюся на текущий момент. Прогноз получается как экстраполяция последней тенденции. Прогнозирование методом среднего и скользящего среднего Наиболее простая модель этой группы обычное усреднение набора наблюдений прогнозируемого ряда y(t+1)=(x(t)+x(t-1)+x(t-2)+ +x(1))/t. При усреднении сглаживаются резкие изменения и выбросы данных, что делает результаты прогноза более устойчивыми к изменчивости ряда, но в целом эта модель прогноза так же примитивна как «наивная». В формуле прогноза на основе среднего предполагается, что ряд усредняется по всем наблюдениям, но старые значения временного ряда могли формироваться на основе иных закономерностей и утратить актуальность. Чтобы повысить точность прогноза, можно использовать «скользящее среднее» y(t+1)=(x(t)+x(t-1)+x(t-2)+ +x(t-t))/(t+1), т.е. модель «видит» прошлое на Т отсчетов времени и прогноз строится только на этих наблюдениях. Иногда метод скользящего среднего оказывается даже эффективнее чем методы, основанные на долговременных наблюдениях. Регрессионные модели Один из методов прогнозирования временных рядов определение факторов, которые влияют на каждое значение временного ряда. Для этого выделяется каждая компонента временного ряда, вычисляется ее вклад в общую
9 составляющую, а затем на его основе прогнозируются будущие значения временного ряда. Данный метод получил название декомпозиции временного ряда. Исходный временной ряд представляется как композиция тренда, сезонной и циклической компоненты. Для построения прогноза выполняется выделение этих компонент из ряда, т.е. разложение ряда по компонентам. Рассмотрим прогнозирование методом декомпозиции с помощью тренда. Если тренд линейный, что типично для многих реальных временных рядов, то он представляет собой прямую линию, описываемую уравнением y=a+b t, где y значение ряда, a и b коэффициенты, определяющие расположение и наклон линии тренда, t время. Если уравнение линии тренда известно, то с его помощью можно рассчитать значение тренда в любой момент времени y t+k =a+b(t +k), где t начало прогноза, k горизонт прогноза. При использовании сезонности для прогнозирования методом декомпозиции сначала из временного ряда убирается тренд и сглаживается возможная циклическая компонента. Тогда можно считать, что оставшиеся данные будут обусловлены в основном сезонными колебаниями. На основе этих данных вычисляются так называемые сезонные индексы, которые характеризуют изменения временного ряда во времени. Например, временной ряд содержит наблюдения по месяцам в течение года. Сезонный индекс, равный 1, будет установлен для месяца, ожидаемое значение в котором составляет 1/12 от общей суммы по месяцам. Если для некоторого месяца устанавливается индекс 1.2, то ожидаемое значение для этого месяца составляет 1/12+20%, а если 0.8 то 1/12-20% и т.д. Ясно, что сумма сезонных индексов за год должны равняться 12. Использовать сезонность для прогнозирования можно тогда, когда сезонные колебания имеют хорошую повторяемость.
ПРАКТИЧЕСКАЯ РАБОТА 2 ИСПОЛЬЗОВАНИЕ МЕТОДА СКОЛЬЗЯЩЕЙ СРЕДНЕЙ В ПРОГНОЗИРОВАНИИ Цель работы: научиться строить тренд временного ряда на основе метода скользящей средней. Содержание работы: 1. Суть метода
ЛЕКЦИЯ 7 ДИНАМИЧЕСКИЕ МОДЕЛИ ОЦЕНИВАНИЕ МОДЕЛЕЙ С РАСПРЕДЕЛЕННЫМИ ЛАГАМИ ВРЕМЕННЫЕ РЯДЫ (ОСНОВНЫЕ ОПРЕДЕЛЕНИЯ) Эконометрические модели, которые в качестве регрессоров включают лаговые переменные, относятся
Лекция 12. Введение в анализ временных рядов Виды временных рядов. Требования, предъявляемые к исходной информации Статистическое описание развития экономических процессов во времени осуществляется с помощью
РАЗДЕЛ. ВРЕМЕННЫЕ РЯДЫ. АНАЛИЗ И ПРОГНОЗ ЭКОНОМИЧЕСКИХ ПОКАЗАТЕЛЕЙ ПО ИХ ВРЕМЕННЫМ РЯДАМ... ВРЕМЕННОЙ РЯД (ОПРЕДЕЛЕНИЯ, ПРИМЕРЫ, ФОРМУЛИРОВКА ОСНОВНЫХ ЗАДАЧ... СТАЦИОНАРНЫЕ ВРЕМЕННЫЕ РЯДЫ И ИХ ОСНОВНЫЕ
ТЕМА 4. АВТОКОРРЕЛЯЦИЯ УРОВНЕЙ ВРЕМЕННОГО РЯДА И ВЫЯВЛЕНИЕ ЕГО СТРУКТУРЫ При наличии во временном ряде тенденции и циклических колебаний значения каждого последующего уровня ряда зависят от предыдущих.
1. Общий анализ временного ряда. 1.1. Проверка гипотезы о случайности временного ряда. График временного ряда изучаемого показателя «Среднедушевые денежные доходы» изображен на рис. «Доходы населения».
Методология Box Jenkins (BJ) или модели AR(I)MA. Модель авторегрессии AR(p). Модель скользящего среднего MA(q). Модель авторегрессии AR(p) Целью эконометрического моделирования часто является так называемое
Эконометрическое моделирование Лабораторная работа 8 Анализ временных рядов Оглавление Понятие и виды временных рядов... 3 Прогнозирование экономических показателей на основе экстраполяции тренда... 3
Методология Box Jenkins (BJ) или модели AR(I)MA. Модель авторегрессии AR(p). Модель авторегрессии MA(q). Целью эконометрического моделирования часто является так называемое ou-of-sample предсказание, т.е.
Тема 10. Ряды динамики и их применение в анализе социально-экономических явлений. Изменение социально-экономических явлений во времени изучается статистикой методом построения и анализа динамических рядов.
МВДубатовская Теория вероятностей и математическая статистика Лекция 4 Регрессионный анализ Функциональная статистическая и корреляционная зависимости Во многих прикладных (в том числе экономических) задачах
УДК 338.4 ПРОГНОЗИРОВАНИЕ ОБЪЕМОВ ПРОДАЖ В МОДЕЛИ УПРАВЛЕНИЯ ЗАПАСАМИ 8 Ю.С. Чуйкова, Б.А. Горлач Ключевые слова: товарные запасы, управление запасами, прогноз продаж, сезонность, тренд, сезонная волна,
АКАДЕМИЯ НАРОДНОГО ХОЗЯЙСТВА ПРИ ПРАВИТЕЛЬСТВЕ РФ Институт Бизнеса и Делового Администрирования Примеры использования дополнительных надстроек MS Excel Анализ модельных временных рядов с помощью надстройки
Абдиев Б.А. «Эконометрика» Предназначено для студентов специальности: Финансы, вечернее отделение (2 курс 4г.о.) Учебный год: 2015-2016 Текст вопроса 1 Парная регрессия у=а+вх+е представляет собой регрессию
55 3 РЕГРЕССИОННЫЙ АНАЛИЗ 3 Постановка задачи регрессионного анализа Экономические показатели функционирования предприятия (отрасли хозяйства) как правило представляются таблицами статистических данных:
ОСНОВЫ РЕГРЕССИОННОГО АНАЛИЗА ПОНЯТИЕ КОРРЕЛЯЦИОННОГО И РЕГРЕССИОННОГО АНАЛИЗА Для решения задач экономического анализа и прогнозирования очень часто используются статистические, отчетные или наблюдаемые
1. Тема: Предпосылки МНК, методы их проверки Предпосылками метода наименьших квадратов (МНК) являются следующие функциональная связь между зависимой и независимой переменными присутствие в эконометрической
ПЛАН-КОНСПЕКТ. ТЕМА 5. МАТЕМАТИКО-СТАТИСТИЧЕСКИЕ МЕТОДЫ ИЗУЧЕНИЯ СВЯЗЕЙ Вопросы: 1. Сущность математико-статистических методов изучения связей 2. Корреляционный анализ 3. Регрессионный анализ 4. Кластерный
46 Глава 9. Регрессионный анализ 9.. Задачи регрессионного анализа Во время статистических наблюдений как правило получают значения нескольких признаков. Для простоты будем рассматривать в дальнейшем двумерные
Порядок выполнения работы. На основе имеющихся данных о производстве продукции за N лет рассчитать следующие величины: темпы прироста производства, производительность труда, производительность капитала.
Динамика рождаемости по Чувашской республике Содержание Введение 1. Общая тенденция рождаемости населения Чувашской республики 2. Основная тенденция рождаемости 3. Динамика рождаемости городского и сельского
3, 01 Г. В. Жукова Ìàòåìàòè åñêèå ìåòîäû èíâåñòèöèîííîãî ïëàíèðîâàíèÿ Аннотация: в данной статье рассмотрены основные математические методы, позволяющие получить прогнозные оценки развития тех или иных
Литература 1. Ханк Д.Э., Уичерн Д.У., Райтс А.Дж. Бизнес-прогнозирование, 7-е издание М.: Изд. Дом «Вильямс», 2003 2. Дуброва Т.А. Статистические методы прогнозирования/м. : ЮНИТИ- ДАНА, 2003 3. Вуколов
План лекций 1 семестр 1. Введение. 1.1. Предмет, метод и задачи статистики; источники статистической информации. 1.2. Кратка история развития статистики. Структура статистических органов на современном
Ср. температура 0 0,97789784683 Ср. осадки 0 0,893300077 Ср.температура/Осадки- 0,005975564 Данные, приведенные в табл. 4 показывают, что наиболее сильные корреляционные связи наблюдаются для среднегодовых
1 (64), 2012/ 33 The offered and realized additive model of calculation of specific norm of consumption of scrap metal at arc electric steel-smelting furnaces has allowed to reduce considerably the error
РЯДЫ ДИНАМИКИ КЛАССИФИКАЦИЯ Ряд динамики (РД), хронологический ряд, динамический ряд, временной ряд это последовательность упорядоченных во времени числовых показателей, характеризующих уровень развития
Прогнозирование в Excel методом скользящего среднего доктор физ. мат. наук, профессор Гавриленко В.В. ассистент Парохненко Л.М. (Национальный транспортный университет) Теоретическая справка. При моделировании
Контрольные тесты по дисциплине «Эконометрика» Первая главная компонента A. Содержит максимальную долю изменчивости всей матрицы факторов. B. Отражает степень влияния первого фактора на результат. C. Отражает
Алеткин П.А., Кожемякова В.В., Шайдуллина Л.И. Прогнозирование доходов и расходов предприятия на основе мультипликативной модели временных рядов В данной практической статье авторами рассмотрено применение
6 целей инвестирования в ИТ (опрос) Повышение эффективности операционной деятельности Новые товары, услуги, бизнес-модели Тесные контакты с покупателями и поставщиками Поддержка принятия решений Конкурентные
Лекция 5. Элементы теории корреляции.. Функциональная, статистическая и корреляционная зависимости. Две случайные величины могут быть связаны функциональной зависимостью, т.е. изменение одной из них по
АВТОМАТИЗАЦИЯ ЭКОНОМЕТРИЧЕСКОГО МОДЕЛИРОВАНИЯ Т. А. Заяц УО «Белорусский торгово-экономический университет потребительской кооперации», г. Гомель В современных экономических условиях планирование и управление
УДК 519.862. Физико-математические науки Летова Марина Сергеевна, студентка Факультет прикладной математики и механики, Федеральное государственное бюджетное образовательное учреждение высшего профессионального
Автокорреляция в остатках. Критерий Дарбина-Уотсона. Бондар Е. В. Филиал Федерального государственного автономного образовательного учреждения высшего образования «Южный федеральный университет» в г. Новошахтинске
ЗАДАЧИ И МЕТОДЫ ПРОГНОЗИРОВАНИЯ В ГОРНОМ ДЕЛЕ Прогнозирование событий, и в частности, последствий разработки полезных ископаемых, чрезвычайно сложное дело из-за взаимосвязанности процессов в биосфере.
Лекция 8 Тема Сравнение случайных величин или признаков. Содержание темы Аналогия дискретных СВ и выборок Виды зависимостей двух случайных величин (выборок) Функциональная зависимость. Линии регрессии.
11. МЕТОДИЧЕСКИЕ УКАЗАНИЯ ДЛЯ ОБУЧАЮЩИХСЯ ПО ОСВОЕНИЮ ДИСЦИПЛИНЫ. Приступая к изучению дисциплины, студенту необходимо внимательно ознакомиться с тематическим планом занятий, списком рекомендованной литературы.
Алеткин П.А., Кожемякова В.В., Шайдуллина Л.И. Прогнозный анализ доходов и расходов от обычных видов деятельности с помощью построения аддитивной модели временного ряда В данной практической статье авторами
Линейная корреляционная зависимость Часто на практике требуется установить вид и оценить силу зависимости изучаемой случайной величины Y от одной или нескольких других величин (случайных или неслучайных).
Кафедра экономики и управления Статистика Учебно-методический комплекс для студентов ФСПО, обучающихся с применением дистанционных технологий Модуль 6 Ряды динамики Составитель: Ст. преподаватель Е.Н.
Иткин В.Ю. Модели ARMAX Семинар 4. Временные ряды. Автокорреляционная функция 4.1. Пример временного ряда Рассмотрим пример: серия измерений давления газа на выходе из абсорбера на УКПГ. На первый взгляд,
Лекция 5 ЭКОНОМЕТРИКА 5 Проверка качества уравнения регрессии Предпосылки метода наименьших квадратов Рассмотрим модель парной линейной регрессии X 5 Пусть на основе выборки из n наблюдений оценивается
Регрессионный анализ регрессионный анализ -введение коэффициент корреляции степень связи в вариации двух переменных величин (мера тесноты этой связи) метод регрессии позволяет судить как количественно
Тема 2.3. Построение линейно-регрессионной модели экономического процесса Пусть имеются две измеренные случайные величины (СВ) X и Y. В результате проведения n измерений получено n независимых пар. Перед
7 (35) 008 Рынок ценных бумаг Применение анализа временных рядов в стратегии инвестора и торговой системе трейдера Е.Е. Лещенко Кафедра менеджмента инвестиций и инноваций Российской экономической академии
Задачи для текущего контроля Задача 1 Администрация банка изучает динамику депозитов физических лиц за ряд лет (млн долл. в сопоставимых ценах). Исходные данные представлены ниже: Сумма Время, лет 1 2
3.4. СТАТИСТИЧЕСКИЕ ХАРАКТЕРИСТИКИ ВЫБОРОЧНЫХ ЗНАЧЕНИЙ ПРОГНОЗНЫХ МОДЕЛЕЙ До сих пор мы рассматривали способы построения прогнозных моделей стационарных процессов, не учитывая одной весьма важной особенности.
НАУЧНЫЙ ВЕСТНИК ИЭП им Гайдарару 5 ПРОГНОЗИРОВАНИЕ В ПЕРИОДЫ ЭКОНОМИЧЕСКОЙ НЕСТАБИЛЬНОСТИ: СУЩЕСТВУЮТ ЛИ ПРОСТЫЕ СПОСОБЫ УЛУЧШЕНИЯ КАЧЕСТВА ПРОГНОЗОВ МТурунцева зав лабораторией ИЭП им ЕТ Гайдара и РАНХиГС
Управление производством УДК 631.15:338.27 ПРОГНОСТИЧЕСКИЕ МЕТОДЫ В УПРАВЛЕНИИ ПРОИЗВОДСТВОМ ЗЕРНОВЫХ КУЛЬТУР Е. Г. НИКИТЕНКО, аспирант кафедры менеджмента Е-mail: [email protected] Ставропольский государственный
Новые возможности программы ФемтоСкан Советы и рекомендации Выпуск 003 Волшебство корреляционного анализа. Часть 1. В сканирующей зондовой микроскопии, и в первую очередь в сканирующей туннельной микроскопии,
36 УДК 68.3.068 А.Ю. СОКОЛОВ, О.С. РАДИВОНЕНКО, Т.В. КОРЧАК Национальный аэрокосмический университет им. Н. Е. Жуковского ХАИ, Украина МЕТОДЫ АНАЛИЗА ВРЕМЕННЫХ РЯДОВ В ЗАДАЧАХ ПРОГНОЗИРОВАНИЯ ВСПЫШЕК ЭПИДЕМИЙ
Эконометрическое моделирование Лабораторная работа 7 Анализ остатков. Автокорреляция Оглавление Свойства остатков... 3 1-е условие Гаусса-Маркова: Е(ε i) = 0 для всех наблюдений... 3 2-е условие Гаусса-Маркова:
Трансформация упорядоченных данных Многие аналитические задачи, например прогнозирование, анализ продаж, динамики спроса, состояния бизнес-объектов и других протяженных во времени процессов, связаны
Эконометрическое моделирование Лабораторная работа Корреляционный анализ Оглавление Понятие корреляционного и регрессионного анализа... 3 Парный корреляционный анализ. Коэффициент корреляции... 4 Задание
ЛЕКЦИЯ Сообщения, сигналы, помехи как случайные явления Случайные величины, вектора и процессы 4 СИГНАЛЫ И ПОМЕХИ В РТС КАК СЛУЧАЙНЫЕ ЯВЛЕНИЯ Как уже отмечалось выше основная проблематика теории РТС это
УДК 674.093 ЭВОЛЮЦИЯ ТРЕНДА И ВНУТРИГОДОВОЙ ДИНАМИКИ КИСЛОТНОСТИ ОСАДКОВ, ВЫПАДАЮЩИХ В ТВЕРИ Ф. В. Качановский В предыдущих публикациях автора рассмотрены различные аспекты проблемы кислотности атмосферных
"УТВЕРЖДАЮ" Заместитель Председателя Правления ОАО "СО ЦДУ ЕЭС" Н.Г. Шульгинов 4 декабря 2007 г. Методика прогнозирования графиков электропотребления для технологий краткосрочного планирования 2007 Содержание.
Корреляционный анализ. Корреляционно-регрессионный анализ выполняется на основе анализа эмпирических данных. Методы такого анализа являются составной частью эконометрики, которая устанавливает и исследует
ЛАБОРАТОРНАЯ РАБОТА N o.1 СЛОЖЕНИЕ ОДНОНАПРАВЛЕННЫХ И ВЗАИМНО ПЕРПЕНДИКУЛЯРНЫХ КОЛЕБАНИЙ Цель работы Целью работы является практическое ознакомление с физикой гармонических колебаний, исследование процесса
Лекция. Основные показатели динамики экономических явлений На практике для количественной оценки динамики явлений широко применяются следующие основные аналитические показатели: абсолютные приросты; темпы
УДК 330.42 Экономические науки Харитонова Дарья Евгеньевна, студентка кафедры прикладной математики, специальность «Математическое и информационное обеспечение экономической деятельности», ФГБОУ ВО «Пермский